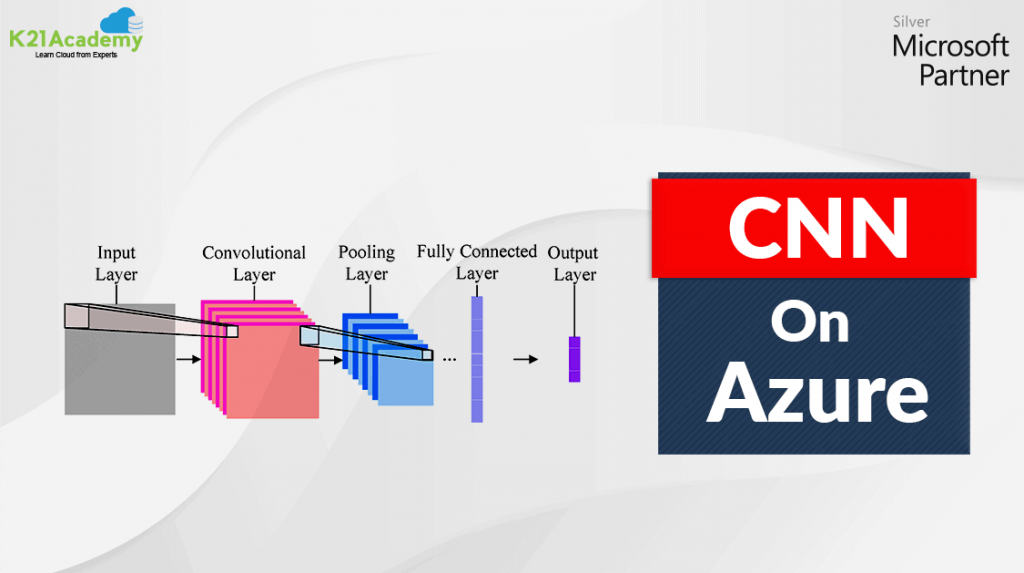
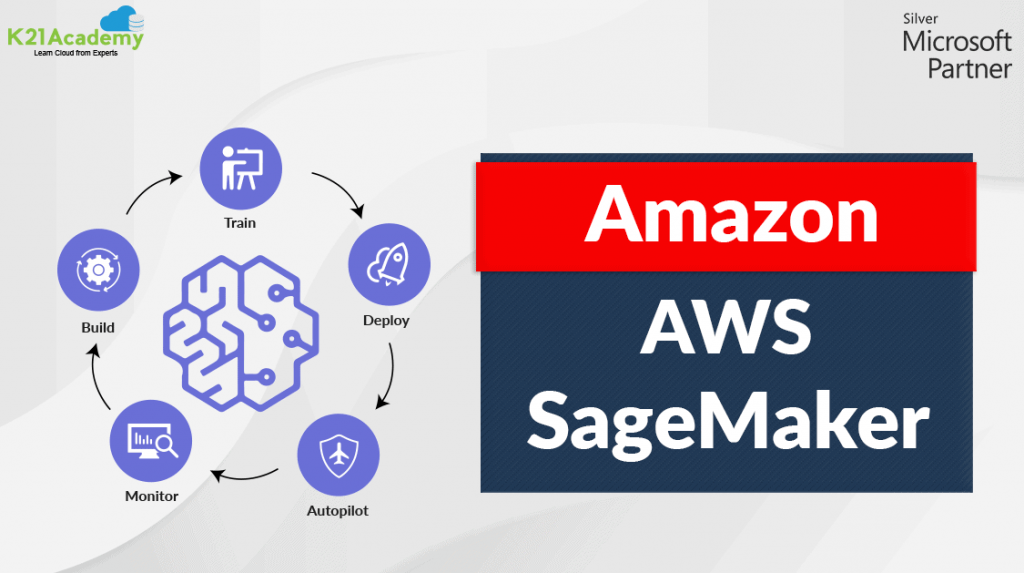
➽ PySpark is a tool developed by the Apache Spark Community to facilitate Python with Spark.
➽ With the use of PySpark, one can integrate and work efficiently with Resilient Distributed Datasets (RDDs) in Python.
➽ Numerous features make PySpark an excellent framework as it facilitates working with massive datasets.
➽ PySpark provides libraries of a wide range, and Machine Learning and Real-Time Streaming Analytics are made easier with the help of PySpark.
𝗦𝗼𝘂𝗻𝗱𝘀 𝗴𝗼𝗼𝗱? 🤔
⚡ For information on Preprocess and Handle Data in PySpark, see https://k21academy.com/azurede35
💫 Want even more in-depth training? Check the FREE CLASS now at https://k21academy.com/azurede02