In this blog, we are going to cover an Introduction To Hive, the Architecture of Hive, features of Hive, and its Limitation on Big data.
Apache Hive is often referred to as ETL and Data warehousing infrastructure tool which is developed on the top of Hadoop file distributed system. Hive is useful for performing operations on Adhoc-queries, Data Encapsulation, and Analysis of huge datasets stored in file systems like HDFS (Hadoop Distributed Framework System).
Hive Data Model
1. Tables
These tables are similar to the RDBMS database tables. We can perform filters, joins, projects, and union of the hive tables. All the data of a table is stored as a directory in HDFS.
2. Partitions
Hive organizes tables into partitions based on partition keys for grouping similar data together.
3. Buckets
The partitions are further categorized into buckets based on the hash function of a column in the table. These buckets are stored as a file in the partition directory.
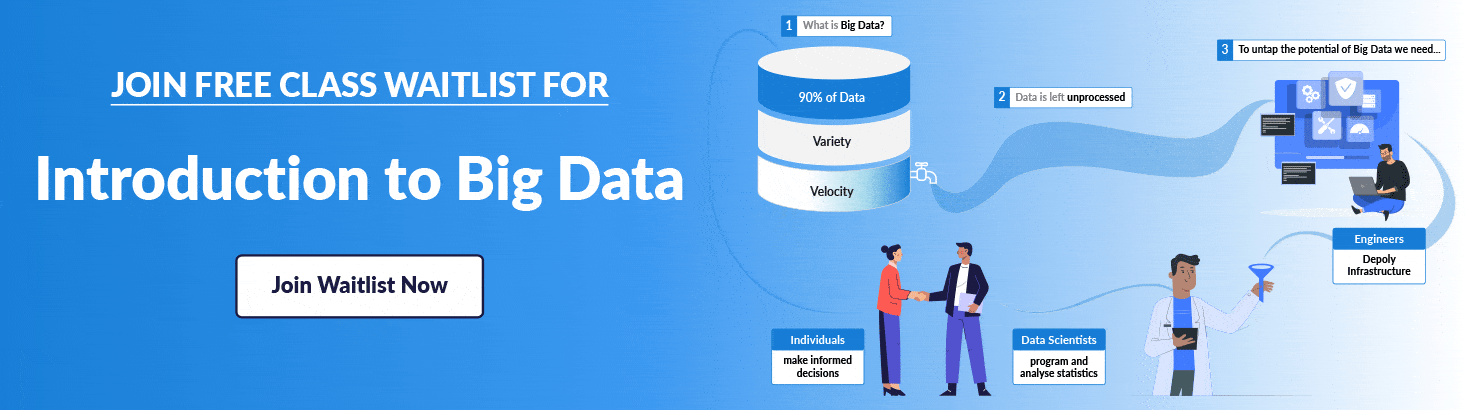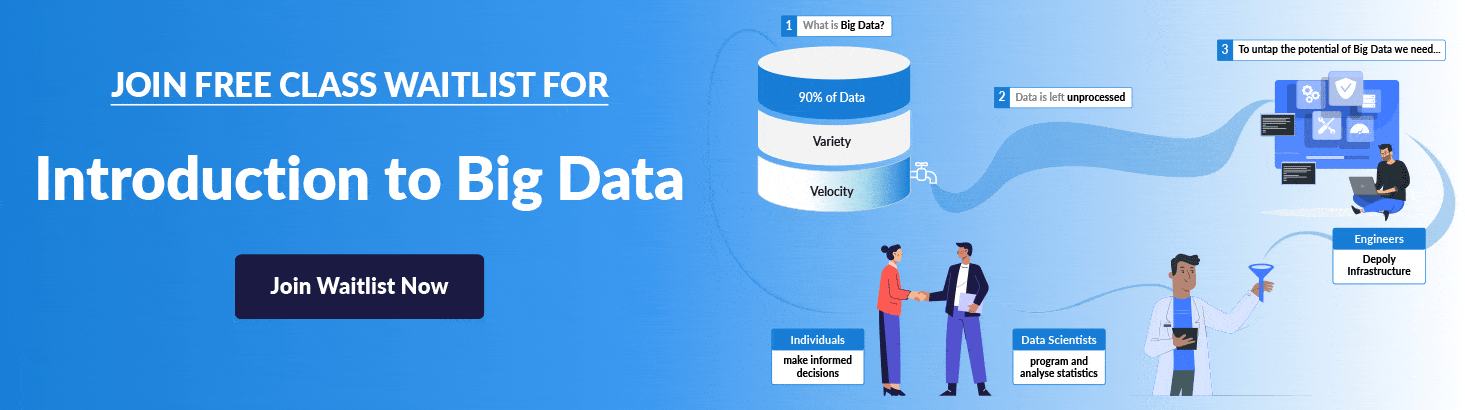
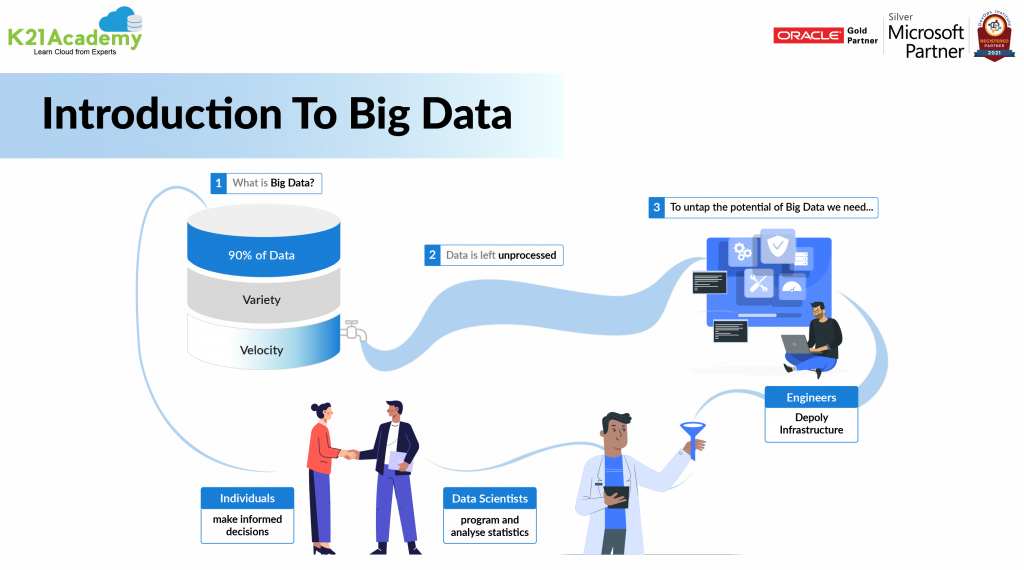
Want to know more about Introduction To Hive | Its Features & Limitations
Read the blog post at https://k21academy.com/bigdata14 to learn more.
Topics we’ll cover :
Introduction
Architecture Of Hive
Hive Data Model
Features of Hive
Limitations of Hive
If you are planning to become a Big Data Engineer , then join the FREE CLASS Waitlist now at . https://k21academy.com/bigdata02